
過去藥物研發依循一套標準流程,通過比如全基因組的測序鑑定並克隆出跟疾病相關的基因,在細胞系和動物模型中進行臨床前驗證,然後經過優化並在動物模型中測試,最後到人體試驗,當中只有部分的藥物能夠最後到達臨床並且開發上市。這種方式已經成功地開發了許多有效治療癌症的藥物,包括乳腺癌及胃癌靶向HER2治療,黑色素瘤BRAF抑制劑及針對非小細胞肺癌的EGFR和ALK抑制劑。儘管基於基因組研究的轉化應用已大幅增加了我們對於疾病的理解,但是理解疾病進展及藥物反應等過程仍舊需要我們更系統地了解基調控、蛋白相互作用和功能的動態和時間差異。此外,識別出有效的生物標誌物,將有助於幫助臨床醫生在臨床治療中依據患者不同分型給予合適的治療方案。
多組學介紹[1-3]
除了基因組學的出現,外顯子學、轉錄組、蛋白組學、表達基因組學(提供基因甲基化信息)也各自提供了不同且更精確豐富的信息。此外,轉錄後修飾(磷酸化及糖基化等)也會影響蛋白功能及下游信號傳導。許多複雜性疾病,比如糖尿病,肥胖以及腸道炎症等,並不能單純通過高通量篩選致病基因而找到病因,還需要綜合考慮外部環境、生活及飲食習慣等因素。因此代謝組學及微生物組學作為多組學研究的一部分,也成為近年來的研究熱點。代謝組學主要研究基因和環境相互作用的關係,不僅能夠鑑定內源性代謝物形式的疾病生物標誌物(基因衍生代謝物)和外源性代謝物(環境衍生的代謝物),還能提供對疾病根本原因的認識。一些研究認為,癌症在某種程度上可以被視為代謝紊亂的結果,例如自體產生的2hydroxyglutarate是一種致癌性代謝物(Oncometabolite),其在神經膠質瘤中的高濃度積累將會間接改變組蛋白的甲基化,從而導致癌症的發生。
迭代的組學分析方法從批量(Bulk)分析,精進到單細胞甚至是空間維度(spatial transcriptomics)使得科學家們能夠繪製出多細胞類型之間相互作用的網絡,為無論是在個體之間還是在個體內部的異質性的存在,揭示了新的疾病機制。高維單細胞技術允許在沒有基因先驗知識的情況下,對細胞進行測序並基於無監督分析依據細胞的轉錄特徵進行分組。舉例來說,2018年發表的健康人群的肝單細胞測序研究確定了20個離散細胞群,提供了人體肝臟的全面概述,以及這些細胞群的重要性及其對肝臟微環境的貢獻;另一研究揭示了肝細胞癌中六種不同的巨噬細胞群體和一類新型的LAMP3+成熟樹突狀細胞,其抑制T細胞抗腫瘤功能。後續的更多研究也圍繞不同組織或腫瘤的數據,對腫瘤免疫治療相關的新抗原(neoantigens),免疫組成(immune contexture),腫瘤微環境(TME)以及宿主和環境因素提供了更多信息。例如,2017發表的Genomic cytometry (CITE-Seq)技術,是在單細胞水平上利用同時無偏差轉錄組測序及基於抗體標記細胞表面蛋白,來獲得更詳細的細胞表型特徵,有助於在臨床樣本(如組織活檢、癌症血液)有限的情況下進行分析。
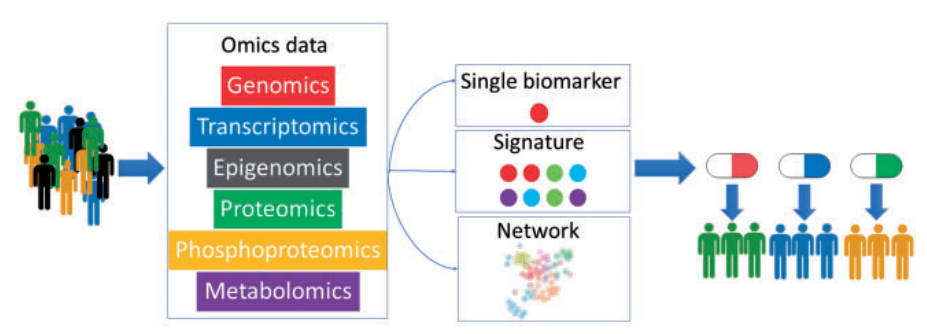
from Brief Bioinform. 2019 May 21;20(3):767-777
舉例多組學的實際應用
多組學的整合已在藥物開發流程中顯現出優勢,且在藥物開發的不同階段均湧現出成功案例。例如在靶點發現階段,利用小鼠和人類腫瘤模型進行全基因組篩選以系統性CRISPR篩選T細胞衰竭的遺傳調節因子圖譜,並找到表觀遺傳狀態的調節分子,可以改善癌症免疫治療中的T細胞反應[4]。
此外,另一涉及重新定位藥物(drug reposition)的研究,通過創建疾病及正常組織樣本的轉錄組表達譜、比較疾病特徵和藥物特徵與疾病基因表達特徵呈逆轉的相關性,科學家們發現了一種新型GABA-B受體激動劑,有望治療非酒精性脂肪性肝炎,並在臨床前藥效模型中得到驗證[5]。
單細胞多組學方法可用於在臨床試驗期間加速細胞生物標誌物的發現,如預測患者對治療的反應,跟蹤反應性細胞類型,並引導設計新的治療策略。例如Docking等人利用多組學比較,鑑定了154名骨髓惡性腫瘤AML患者的多組學信息並制訂了新的AML預後評分,這個研究也體現出轉錄組分析可以為特定患者提供新的治療選擇[6]。
以肝癌為例,針對病人群體檢測DNA copy數目之間的變化以及 somatic mutation以及檢測DNA甲基化,轉錄組、Micro RNA的表達以及蛋白之間的表達,結果顯示,肝癌可分為三個亞型,其中一個相較於另外兩個有較差的預後,此外每種亞型獨特的分子特徵及其不同的預後意味着需要不同的治療策略[7]。
史丹福大學醫學院Mike Snyder 博士帶領的集成的個人組學分析(integrated personal omics profiling (iPOP))以及西雅圖系統生物學研究所(ISB)Leroy Hood博士建立的P4 medicine (predictive, preventive, personalized and participatory)項目定期收集數千位志願者的多組學數據,一方面可用於評估每個人的健康狀況並提高我們對疾病的理解,另一方面也有助於建立個人特定的生物標誌物檔案,以評估精準醫療的可行性。例如,iPOP分析對象的多數患者處於糖尿病早期,通過動態組學數據云可以了解疾病進展與生活方式、治療方案等多種因素之間的相互關係。
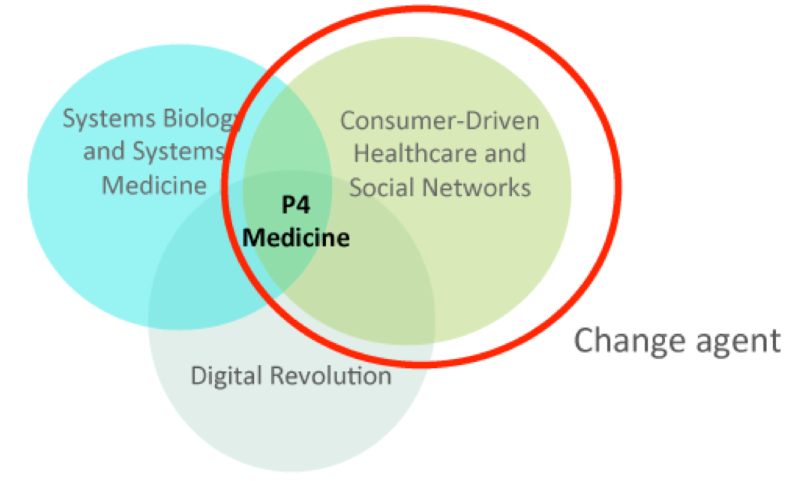
from https://www.esprevmed.org/p4-medicine/
機器深度學習方法助力組學整合及應用
近年來新興開發的複雜機器學習技術已開始利用各領域大數據和深度學習加速藥物研發流程,包括預測化合物物理性質和生物活性,生成新化合物,預測新的合成路徑等。例如通過同源建模的方式,加速新冠病毒相關藥物的標靶預測及篩選。基於多組學的模型訓練無監督深度學習方法,也被成功用於預測肝細胞癌患者的生存期。深度學習通常需要大量的可靠數據樣本來訓練精確的模型。然而,臨床樣本的稀缺性和高異質性為建模帶來不小挑戰。2018年的一項泛癌分析表明,部分肝癌患者的肝臟樣本和乳腺癌具有相同的細胞亞群,都具有ER-α、AR和GFBP2的高表達特徵。因此,通過與其他癌症組學數據進行大規模比較,將有助於理解肝細胞癌機制,並通過借鑑其他癌種的現有療法來指導肝細胞癌的治療方案。
結語
多個轉化模型(細胞系,類器官,動物模型,患者)、新興數據類型(例如,微生物組代謝組數據)、真實世界的證據數據(例如成像和電子醫療數據)和生物標誌物數據(特別是非侵入性生物標誌物)的整合將全面指導未來藥物開發。火星登陸計劃旨在招募志同道合的夥伴,通過開發新的整合方法、分析多組學數據,加速對靶點開發優先級別的評估,針對複雜性疾病提出有效的多靶點治療方案。
參考文獻
[1] Zielinski J. M. et al., Front Immunol. 2021 Mar 31;12:590742.
[2] David S Wishart. Nat Rev Drug Discov. 2016 Jul;15(7):473-84.
[3] Papalexi E. and Satija R. Nat Rev Immunol. 2018 Jan;18(1):35-45
[4] Belk J.A. et al., Cancer Cell. 2022 Jul 11;40(7):768-786.e7.
[5] Bhattacharya D et al., Sci Rep. 2021 Oct 21;11(1):20827.
[6] Docking T.R. et al., Nat Commun. 2021 Apr 30;12(1):2474.
[7] Chen B. et. Al., Nat Rev Gastroenterol Hepatol. 2020 April ; 17(4): 238–251.